KAME: Sakana AI’s Tandem Speech-to-Speech Architecture Combines Speed and Knowledge
Introduction
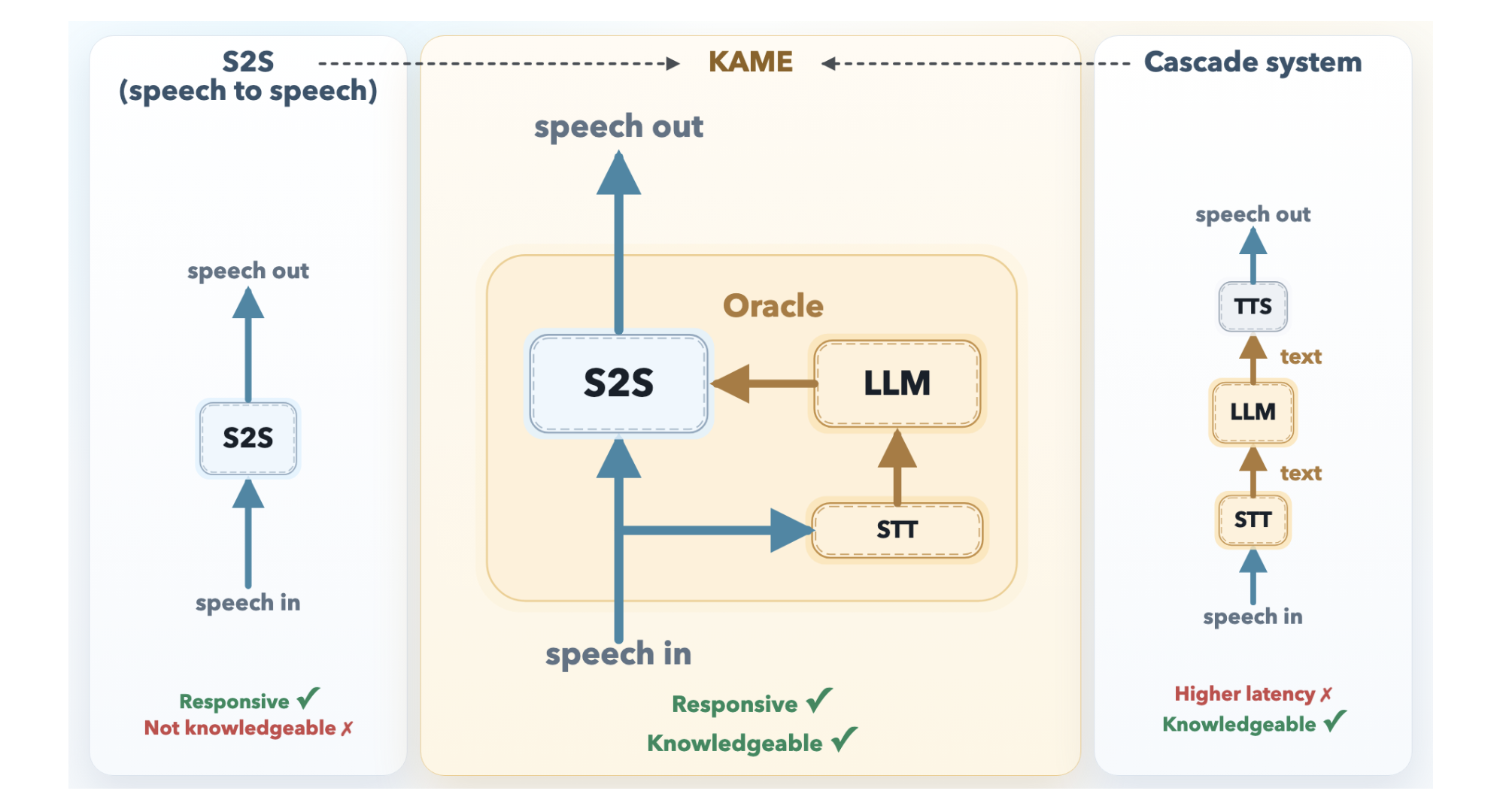
Conversational AI has long faced a dilemma: responses can be either fast or smart, but rarely both. Real-time speech-to-speech (S2S) models, like those powering natural voice assistants, begin speaking almost instantly but often deliver shallow answers. Cascaded systems, which route speech through a large language model (LLM), provide far deeper knowledge but introduce delays that disrupt conversation flow. Tokyo-based Sakana AI has introduced KAME (Knowledge-Access Model Extension), a hybrid architecture that achieves near-zero latency while injecting rich LLM knowledge in real time.
The Problem: Two Paradigms, Two Tradeoffs
Understanding why KAME is groundbreaking requires examining the two dominant designs it bridges.
Direct S2S Models
Direct S2S models, such as Moshi from KyutAI, are monolithic transformers that process audio tokens in a continuous loop, outputting audio directly. They do not need to synchronize with external systems, so response latency is exceptionally low—often starting a reply before the user finishes speaking. However, because acoustic signals carry far more information than text, these models must devote significant capacity to modeling paralinguistic features like tone, emotion, and rhythm. This leaves limited room for factual knowledge and deep reasoning.
Cascaded Systems
Cascaded systems take a different approach: user speech passes through Automatic Speech Recognition (ASR) to produce text, which is fed into a powerful LLM, and the LLM’s response is converted back to speech via Text-to-Speech (TTS). The knowledge quality is excellent—any frontier LLM can be used. But the system must wait for the user to finish speaking before ASR and LLM processing can begin. The result is a median latency of about 2.1 seconds, long enough to interrupt natural conversational rhythm.
KAME’s Architecture: Speaking While Thinking
KAME operates as a tandem system with two asynchronous components running in parallel.
Front-End S2S Module
The front-end S2S module, built on the Moshi architecture, processes audio in real time at discrete audio token cycles (approximately every 80 milliseconds). It immediately begins generating a spoken response. Internally, Moshi’s original three-stream design—input audio, inner monologue (text), and output audio—is extended in KAME with a fourth stream: the oracle stream. This is the key innovation.
Back-End LLM Module
The back-end module consists of a streaming speech-to-text (STT) component paired with a full-scale LLM. As the user speaks, the STT component continuously builds a partial transcript and periodically sends it to the back-end LLM. For each partial transcript, the LLM generates a candidate text response—called an oracle—and writes it to the oracle stream. The front-end S2S module reads from the oracle stream and uses these predictions to influence its real-time output, blending fast local generation with deep LLM knowledge.
This asynchronous design means the S2S module never waits for the LLM; it starts speaking immediately and incorporates LLM insights as they become available. The result is a system that provides the responsiveness of a direct S2S model and the knowledge depth of a cascaded system.
Benefits and Applications
KAME’s tandem approach offers several advantages:
- Low latency: The front-end module begins speaking in under 100 milliseconds, maintaining natural conversational flow.
- Rich knowledge: The back-end LLM supplies factual accuracy and reasoning abilities without blocking the audio stream.
- Scalability: The LLM can be upgraded independently of the S2S front end, allowing future improvements without rebuilding the entire system.
- Natural interaction: By speaking while thinking, KAME reduces the disjointed feel common in cascaded systems.
Potential applications include advanced voice assistants, real-time translation, interactive tutoring, and customer service bots where both speed and accuracy are critical.
Conclusion
KAME represents a significant step forward in conversational AI. By elegantly combining a direct S2S model with an asynchronous LLM knowledge stream, Sakana AI has resolved the long-standing speed-versus-intelligence tradeoff. As the system evolves, it could become the foundation for more natural and capable voice interfaces.